Two ways of using Redis to build a NoSQL autocomplete search index
 |
| Consider a NoSQL solution such as Redis the next time you need to implement search... |
Last week I demonstrated how to setup autocomplete in a new Rails 3.1 app using the Soulmate gem, from SeatGeek. Soulmate uses Redis to cache all of the autocomplete phrases in memory, providing lightning fast query results. While autocomplete is a very useful feature and a common web site design element, what really interests me about Soulmate are the ideas and detailed techniques behind how it uses a NoSQL Redis database to implement autocomplete search.
Today I’m going to take a look at two good examples of creating a search index using Redis: I’ll start with Salvatore Sanfilippo’s original algorithm for autcomplete with Redis, which uses a single sorted set to hold autocomplete prefixes. Then I’ll look at Soulmate’s solution, which also uses Redis but in addition supports matching multiple words in a phrase. I hope that these two examples will inspire you to consider using Redis the next time you need to implement any search related feature, not just autocomplete.
How autocomplete is traditionally implemented with a SQL database
Ruby on Rails has supported autocomplete for years; DHH himself wrote the original autocomplete plugin years ago, and today’s there’s a newer, modern gem called rails3-jquery-autocomplete. Autocomplete uses Javascript to display a list of available options that match the first few letters a user types; for example, here’s the autocomplete field I implemented last week in a sample Rails 3.1 app:
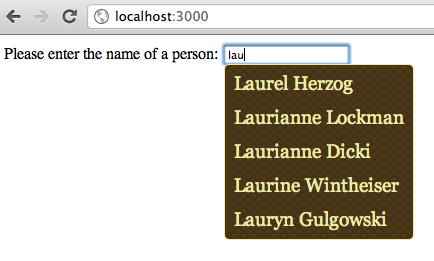
Traditionally Rails gems and plugins have implemented this on the server using a SQL statement similar to this:
SELECT first_name FROM people WHERE LOWER(name) LIKE "lau%"
This SQL statement asks the database server to look through all of the rows in the “people” table, and to find just the people whose first name starts with the given letters. While this works just fine, it can slow down significantly if you have thousands or millions of records since the database needs to perform a string comparison to find the proper rows. You would likely have to instruct the database server to build an index on the first_name field... and hope that it supports fast string search operations with that index.
Creating an autocomplete index using a Redis sorted set
Salvatore Sanfilippo (@antirez), the author of Redis, wrote a great article back in September 2010 called Auto Complete with Redis, which illustrates how to use a Redis Sorted Set object to implement an autocomplete solution. I strongly encourage you to read it to get all the details; he shows an actual solution implemented with Ruby, and also covers the computer science theory behind it’s performance and memory usage.
Instead of relying on a RDBMS database server index to find the matching autocomplete terms, Antirez implements his own search index using Redis! He calculates ahead of time what all the possible prefixes are that a user might type in, and then inserts them all into a Redis Sorted Set object. For example, let’s suppose I want to allow users to select a task from this list - my actual to do list for this morning:
- Take out the trash
- Talk to the school bus driver
Antirez’s code would first figure out the possible prefixes or matching letter combinations that a user might type in. In my example the task phrases start with the words “take” and “talk,” which gives us these possible prefixes:
t
ta
tak
take
tal
talk
Then Antirez adds these prefixes to a sorted set using the Redis ZADD command, like this:
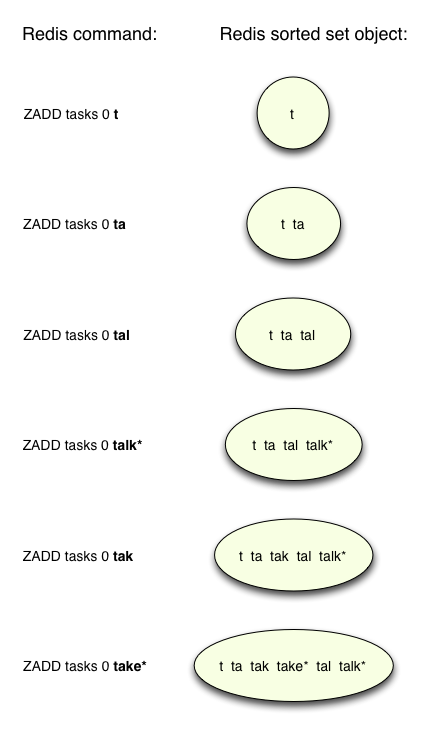
Along with the prefixes, you may have noticed that Antirez also inserted the two actual, complete words into the set as well, each with a trailing asterisk character. As we’ll see in a moment, this allows Antirez’s code to later find the complete words that need to be returned to the user in the autocomplete drop down.
To learn more about Redis Sorted Sets and all of the available commands for them see redis.io, which has a nicely implemented Redis command reference page. The key concept behind sorted sets is that they do the sorting at insertion time - that is, the set is always sorted since each element is inserted into the proper location in the set.
Searching a sorted set for matching words
Now let’s suppose a user starts to type a few letters into a web form: “ta” for example. Antirez’s code would be able to find the matching words, “take” and “talk,” using the following simple Redis commands:
redis 127.0.0.1:6379> ZRANK tasks ta (integer) 1
The ZRANK command searches the given set and returns the index of the given value. Here it would return 1, since “ta” is the second value and Redis uses 0-based indexes.
redis 127.0.0.1:6379> ZRANGE tasks 1 50 1) "ta" 2) "tak" 3) "take*" 4) "tal" 5) "talk*"
ZRANGE returns the 50 prefixes following “ta”, including the two complete words “take” and “talk.”
The code Antirez shows on his blog post then searches through the values returned by ZRANGE looking for the trailing asterisk, in order to find the complete words that match. Since the set is sorted, his code returns the matching words in the proper order, sorted alphabetically. His code also makes additional ZRANGE calls if necessary to find the requested number of matching complete words.
Creating a search index using a Redis hash and multiple sorted sets
The algorithm used by the Soulmate gem is similar, and was inspired by Antirez’s solution. However, SeatGeek used a more complex search index in order to support autocomplete on multiple words, or phrases, at the same time. Let’s take a look at how that works next.
First, Soulmate creates a Redis Hash object and saves all of the autocomplete phrases by repeatedly calling the HSET command, like this:

HSET is very simple: it saves a value into a Redis Hash object, using the given key. This works almost the same way that a Ruby hash does, saving the data in memory. You’ll notice that the value for each hash element is encoded using JSON; this is a convenient way to serialize Ruby objects into a string and then to save them in Redis. Soulmate calls the hash “soulmate-data:tasks,” including the model name or data type in the Redis object key/name. Soulmate also uses the common Redis naming convention of using a colon character to separate various words concatenated together in Redis object names.
Once all of the phrases are saved into the Redis hash, Soulmate then proceeds to generate all the possible prefixes for all of the words appearing in the phrases, the same way that Antirez did above, for example:
Take: ta tak take
The: th the
Bus: bu bus
Talk: ta tal talk
etc....
Soulmate then generates a separate sorted set for each unique prefix, like this:
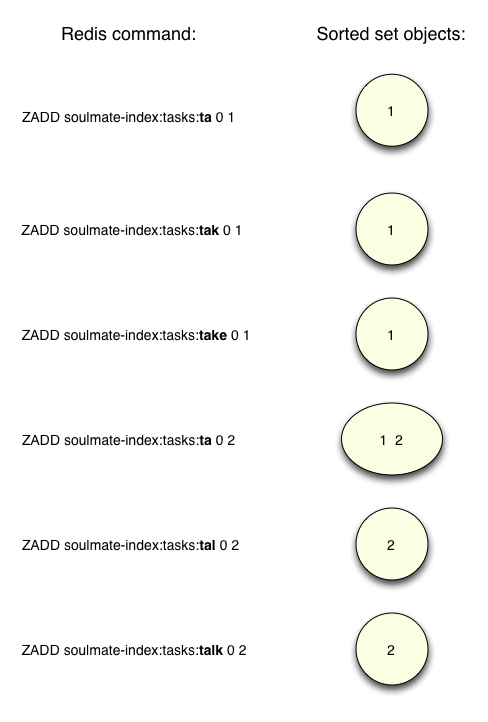
Things to note here are:
- There’s a separate sorted set for each prefix.
- Each prefix is contained in the set name itself, e.g. “soulmate-index:tasks:tak.”
- The elements of the sets are not the prefixes, but instead the keys into the Redis hash created above indicating which phrases contain each prefix.
- The second parameter to ZADD, a zero, is not used here but could be used to set the sort order of the set elements. This is called the “score.”
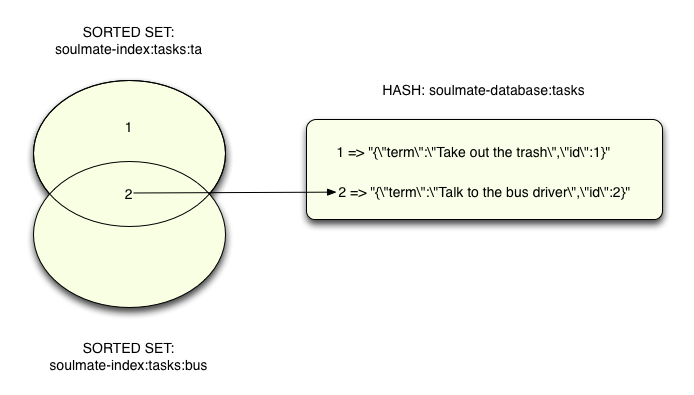
For example, looking at the set for the prefix “tak,” we can see there’s a single value of “1,” the key in the hash above for the “Take out the trash” task. And for the “Ta” prefix, there are two values: “1” and “2” since both phrases contain “Ta” (“Talk” and “Take”). I’ve also left out many other prefixes here to keep things simple; Soulmate would actually calculate prefixes from all the words in each phrase: “the,” “bus,” “driver,” “trash,” etc., and create additional sets for each one.
Intersecting multiple sorted sets to find matching Redis hash keys
Creating all of these different sorted sets allows Soulmate to associate multiple phrases with a single prefix. Let’s see how that works: If the user starts to type “ta” then Soulmate will just need to find the “soulmate-index:task:ta” set:
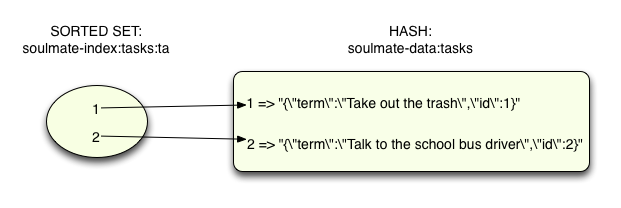
Now by calling the ZRANGE command to get all of the set’s elements (0 means start from the first element, and -1 means continue until the end)...
redis 127.0.0.1:6379> ZRANGE soulmate-index:tasks:ta 0 -1 1) "1" 2) "2"
...Soulmate can get a list of ID values that are also keys into the phrase database hash. Finally Soulmate can load the matching phrases and return them, using the HMGET (hash multiple get) command:
redis 127.0.0.1:6379> HMGET soulmate-data:tasks 1 2
1) "{\"term\":\"Take out the trash\",\"id\":1}"
2) "{\"term\":\"Talk to the school bus driver\",\"id\":2}"
This all happens without a single SQL command, and all of the data values are fetched directly from memory and not from disk!
But that’s not all; as I said above Soulmate also supports the ability to search for multiple prefixes at the same time. For example, suppose the user has typed in “ta bus” ... meaning she wants to match “Talk to the school bus driver” but not “Take out the trash.” How does this work? Well Soulmate will get two sorted sets, once for “ta” and one for “bus” like this:
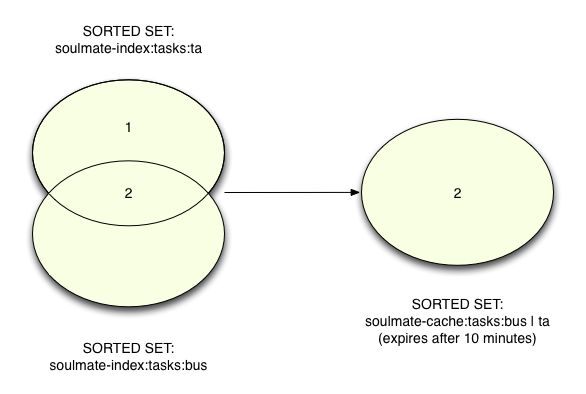
Here Soulmate uses Redis’s ZINTERSTORE command to calculate the intersection between two sets:
redis 127.0.0.1:6379> ZINTERSTORE soulmate-cache:tasks:bus|ta 2
soulmate-index:tasks:ta soulmate-index:tasks:bus
(integer) 1
redis 127.0.0.1:6379> ZRANGE soulmate-cache:tasks:bus|ta 0 -1
1) "2"
This creates a third set called “soulmate-cache:tasks:bus|ta” containing only the elements that appear in both of the first two sets. ZINTERSTORE will actually support intersecting as many sets as you would like. Now Soulmate has the id values of the phrases that match both “ta” and “bus” - in this case 2 but not 1. It uses the name “soulmate-cache:tasks:bus|ta” since the contents of this set reflect which phrases match “bus” and “ta.”
Caching and expiring values with Redis
The last bit of magic in Soulmate’s algorithm that I’ll cover today is caching. To speed things up even further, Soulmate saves the result of the ZINTERSTORE call - the third set created with the common ID elements - for future lookups in case the same user or a different user types exactly the same letters again. Here’s how that works:
The intersection set was actually saved above in the call to ZINTERSTORE, and now to indicate that it should expire after 10 minutes (600 seconds) we would use:
redis 127.0.0.1:6379> EXPIRE soulmate-cache:tasks:bus|ta 600 (integer) 1
There are two important Redis concepts to learn here:
- Note how the intersection result set is labelled with the name “soulmate-cache:tasks:ta|bus” - this is a common Redis pattern. Key names can be long and complex, are often can contain multiple values concatenated together. In this case the two prefixes the user was searching for are containing right in the key name, allowing Soulmate to look it up easily in subsequent calls.
- Redis objects can be set to automatically expire, making it easy to keep cached values for a short time to speed up queries while preventing them from becoming stale by remaining in memory for too long. Soulmate sets these cache sets to expire after 10 minutes.
Now you can see the entire Soulmate search algorithm is then just as simple as:
- Take the prefixes typed in by the end user
- Look for a “soulmate-cache:tasks:XX|YY|ZZ” sorted set
- If there is no such set, find the sorted set for each of the prefixes using the pattern “soulmate-index:tasks:XX” and call ZINTERSTORE on them to create it. Then set it to expire after 10 minutes with EXPIRE.
- Call HMGET to get the matching autocomplete phrases using the id’s found in the sorted set
- Return them to the user
Conclusion
This might seem like a lot of trouble and hassle to go through in order to implement something as simple as autocomplete - after all, to get autocomplete to work using a traditional SQL RDBMS all I need to do is issue a simple SELECT statement and I’m done. If there’s a lot of data to search through then maybe I need to create a SQL index on the proper column.
What Salvatore Sanfilippo and the SeatGeek team have done here is to implement their own custom search index - but why bother? Redis is a powerful tool with many commands, but they are all very low-level and not nearly as powerful as a real SQL statement running on an RDBMS server.
The simple reason why is: using a NoSQL database like Redis gives you exactly the functionality and behavior you need to solve your problem, to create your search index, and nothing more. And since you don’t have to pay the price of compiling, analyzing and processing a SQL statement it will be very, very fast compared to using a traditional SQL database server. Also since Redis’s commands are so low-level, you are free to implement your search index any way you would like: you can customize it to fit your data model and design needs precisely. In a way, using Redis is a more agile solution... build just what you need to search your own data, instead of using an overly complex tool designed to solve every problem.


